Archivos de Datos. Nueva Base de Datos (II)
Muy bien, ahora enfoqué monos en cada una de las columnas que aparecen en la Vista de variables , para analizar cada una de sus propiedades.
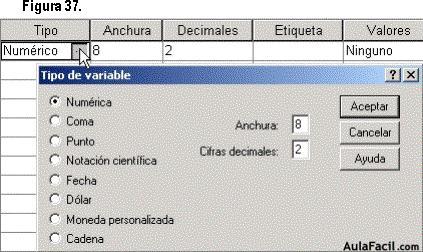
Una vez colocado el nombre de la variable , se nos presenta el Tipo de variable que se trate, especifica los tipos de datos de cada variable. Por defecto se asume que todas las variables nuevas son numéricas. En nuestro caso, dejaremos la variable género como de tipo cadena (alfanumérica), con una anchura de 8 caracteres (figura 37).
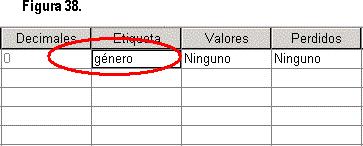
Uno de los puntos muy importantes y que debe ponérsele mucho énfasis es la etiqueta , ya que así aparecerá la variable en nuestras tablas de análisis. Continuando con el ejemplo anterior, seguiremos trabajando con el nombre de “género” y así etiquetaremos la variable. En algunos casos, cuando el nombre sea muy extenso, es recomendable utilizar abreviaturas que identifiquen cada una de las variables, como por ejemplo: “latino” (Latinoamericano), “estud” (estudiante), “cirplast” (Cirujano Plástico), etc. La figura 38 nos muestra como se va transformando hasta ahora nuestra base de datos.
Ahora pasamos a la opción de Valores , que es donde combinamos números con palabras, que nos servirá para identificar características o atributos con un simple número y viceversa.
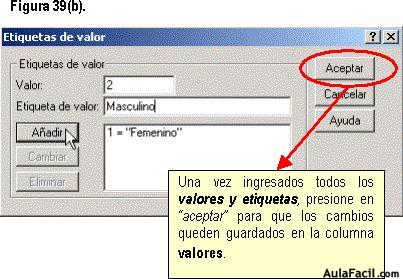
Para comenzar, damos un clic en la casilla en donde aparece hasta el momento “ninguno” en valores, como se observa en la figura 39, y aparece el recuadro de “etiquetas de valor”.
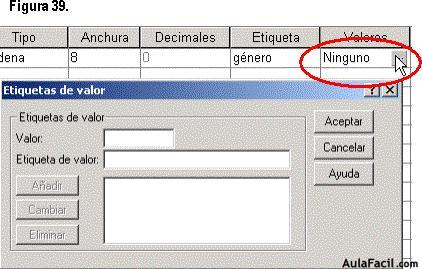
Cuando tenemos el recuadro, lo que debemos hacer es codificar nombres con números, asociando de esta forma un número para una característica o atributo del sujeto. Entonces, para nuestro caso de la variable “género”, se designará de la siguiente forma:
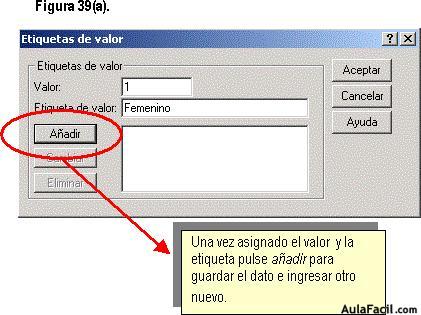
- Número 1 para “femenino”, y
- Número 2 para “masculino”.
Una vez hecho esto, se pulsa en el botón “añadir” para que agregue las nuevas etiquetas de valor. La figura 39(a) muestra este proceso.
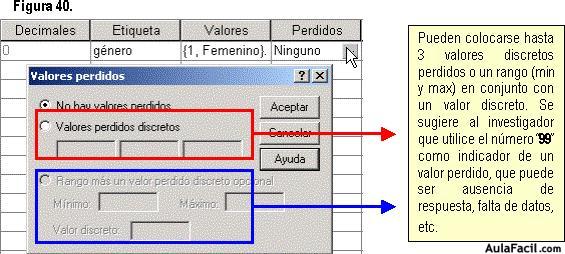
Ahora seguimos con la opción de perdidos . Acá se definen valores de los datos especificados como perdidos por el usuario. A menudo es útil para saber por qué se pierde información. Por ejemplo, puede desear distinguir los datos perdidos porque un entrevistado se niega a responder, o datos perdidos porque la pregunta no afectaba a dicho entrevistado, etc. Los valores de datos especificados como perdidos por el usuario aparecen marcados para un tratamiento especial y se excluyen de la mayoría de los cálculos. Para nuestra base de datos ejemplo, asumiremos que no se tienen valores perdidos.
