Análisis de Componentes Principales (I)
Cuando afrontamos un Análisis Multivariante de datos, el escenario típico suele estar constituido por una masa de datos generalmente grande no sólo porque suele proceder de muchos individuos (muchos casos), sino también porque sobre cada uno de esos individuos se suele medir un número sustancial de variables.
Generalmente, la información que proporcionan estas “muchas” variables suele ser en buena parte redundante al presentarse entre ellas múltiples relaciones de dependencia manifestadas por la existencia de correlaciones considerables. Así, al explicar el comportamiento de los datos, de una forma clara (o al menos sencilla), a partir de esas variables inicialmente observadas y altamente correlacionadas resulta una tarea dificultosa.
Las técnicas factoriales pretenden, desde sus diferentes enfoques, abordar el problema de simplificar la interpretación del comportamiento observado de los datos.
Para ilustrar brevemente algunos de estos enfoques, imaginemos que disponemos de las calificaciones en nueve asignaturas de los 29 alumnos de un curso, según se indica en el cuadro siguiente (lista detallada de datos en el ejemplo al final del tema):
Caso | ST1 | ST2 | GES | ST3 | IOP | INF | MAT | ECO | ING |
1 | 0,3 | 0,3 | 1,0 | 0,0 | 1,7 | 0,6 | 0,6 | 0,6 | 0,3 |
*** | *** | *** | *** | *** | *** | *** | *** | *** | *** |
15 | 6,2 | 6,5 | 4,1 | 4,2 | 2,4 | 3,4 | 5,5 | 6,2 | 5,8 |
*** | *** | *** | *** | *** | *** | *** | *** | *** | *** |
29 | 10,0 | 10,0 | 9,6 | 8,7 | 9,6 | 9,3 | 10,0 | 7,2 | 7,5 |
Variables: Estadística 1 (ST1), Estadística 2 (ST2), Estadística 3 (ST3), Investigación Operativa (IOP), Informática (INF), Matemáticas (MAT), Economía (ECO), Gestión (GES) e Inglés (ING).
Ya en una primera aproximación podemos comprobar la dificultad de visualizar esta información de manera completa. Nuestra limitada percepción intuitiva de las cosas, acostumbrada a espacios físicos de 3 dimensiones (o a lo sumo 4 si incorporamos el tiempo), puede permitirnos imaginar la existencia de un espacio de nueve dimensiones como el de nuestro ejemplo, pero difícilmente nos permite visualizar lo que ocurre en él y que los datos manifiestan.
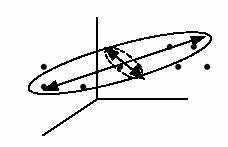
Podemos tratar de vislumbrar este comportamiento global en ese espacio complejo, a partir de sus proyecciones resultantes sobre los sub-espacios formados por cada dos ó tres de esas nueve variables; lo que podemos representar y comprender bastante bien mediante gráficos bidimensionales o tridimensionales.
En estas representaciones, las nubes de puntos proyectados aparecerán más alargada en aquella dirección donde se presente una mayor dispersión o variabilidad (en general, mayor variedad o diversidad) de los datos, y menos alargada en aquella dirección donde haya una menor dispersión o variabilidad (en general, menor variedad o diversidad) de los datos, como intuitivamente puede verse en el anterior gráfico.
